HadooP – The Beginning
What is Hadoop?
- Open-source data storage and processing API

- Scales to Petabytes or more
- Parallel data processing
- Suited for particular types of BigData problems
Companies Using Hadoop
- Facebook,Yahoo,Amazon
- eBay
- American Airlines
- The New York Times
- Federal Reserve Board
- IBM,Orbitz
Basics of Hadoop
Hadoop is a set of Apache Frameworks and more…
- Data storage (HDFS)
- Runs on commodity hardware (usually Linux)
- Horizontally scalable
- Processing (MapReduce)
- Parallelized (scalable) processing
- Fault Tolerant
- Other Tools / Frameworks
- Data Access
- HBase, Hive, Pig, Mahout
- Tools
- Hue, Sqoop
- Monitoring
- Greenplum, Cloudera
- HDFS Storage
- Redundant (3 copies)
- For large files large blocks
- 64 or 128 MB / block
- Can scale to 1000s of nodes
- MapReduce API
- Batch (Job) processing
- Distributed and Localized to clusters (Map)
- Auto-Parallelizable for huge amounts of data
- Fault-tolerant (auto retries)
- Adds high availability and more
- Other Libraries
- Pig
- Hive
- HBase
- Others
Hadoop Cluster HDFS (Physical) Storage

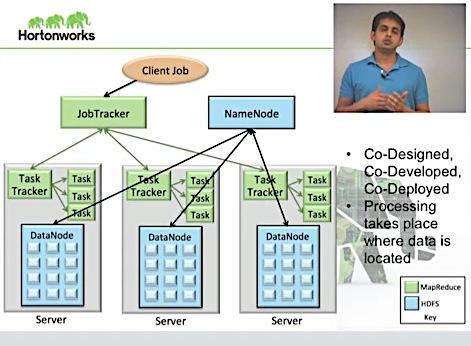
Hadoop Map Reduce Fundamentals

Maximum ppl uses Java for MapReducing
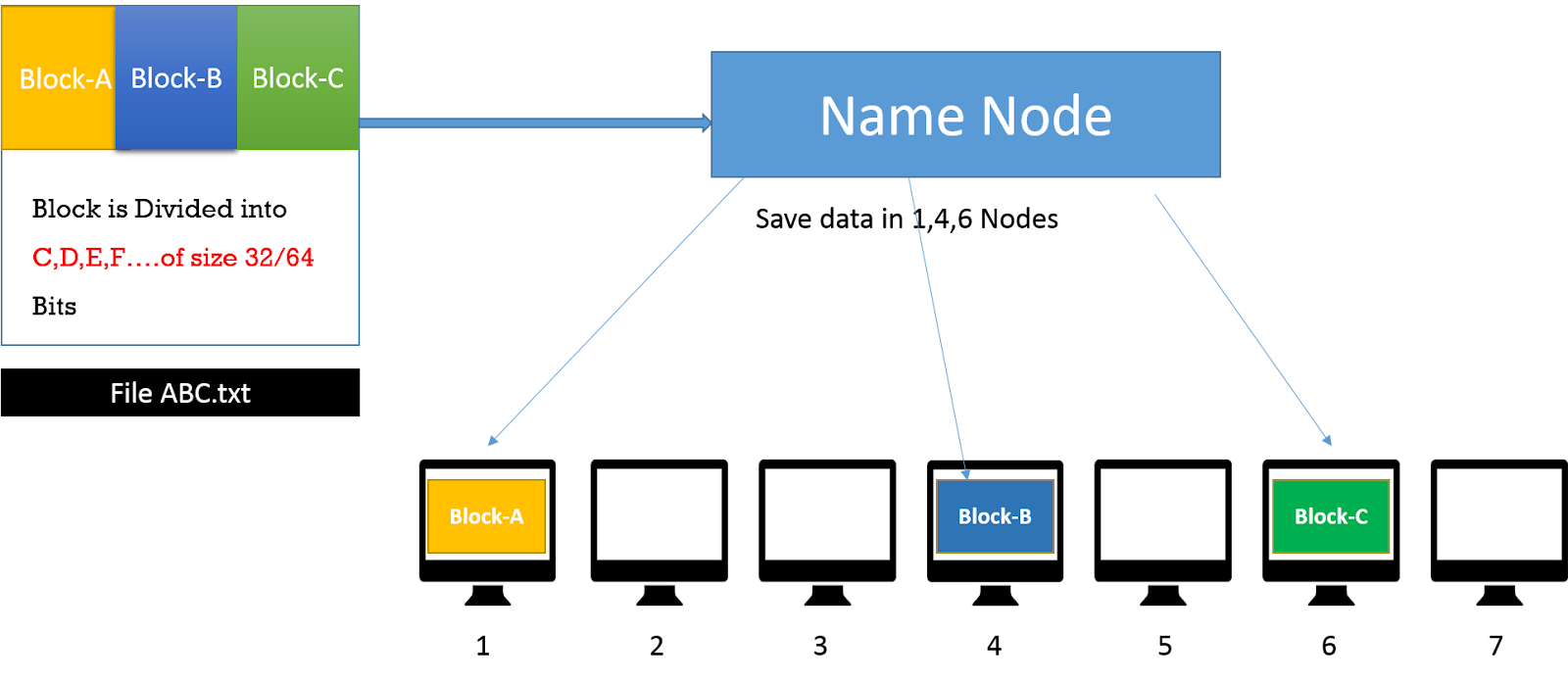
Name Node: 0.0.0.0:8202, means a normal PC with Some Hard disc space which is connected to Hadoop Network
What is Hive?
- a data warehouse system for Hadoop that
- facilitates easy data summarization
- Supports ad-hoc queries (still batch though…)
- created by Facebook
- a mechanism to project structure onto this data and query the data using a SQL-like language HiveQL
- Interactive-console or-
- Execute scripts
- Kicks off one or more MapReduce jobs in the background
- an ability to use indexes, built-in user-defined functions
- File Size → 64mb / 128Mb
- Data Storage → Local System, HDFS / Cloud
- Output → Immutable, Not savable
- We have to write →Inuput → MapReduce → Output
How to Query the Hadoop database?
Hadoop is NOT Database, IT IS <KEY, VAR> pair
Input → split → key-value generated → mapping →shuffle → reduce → Output
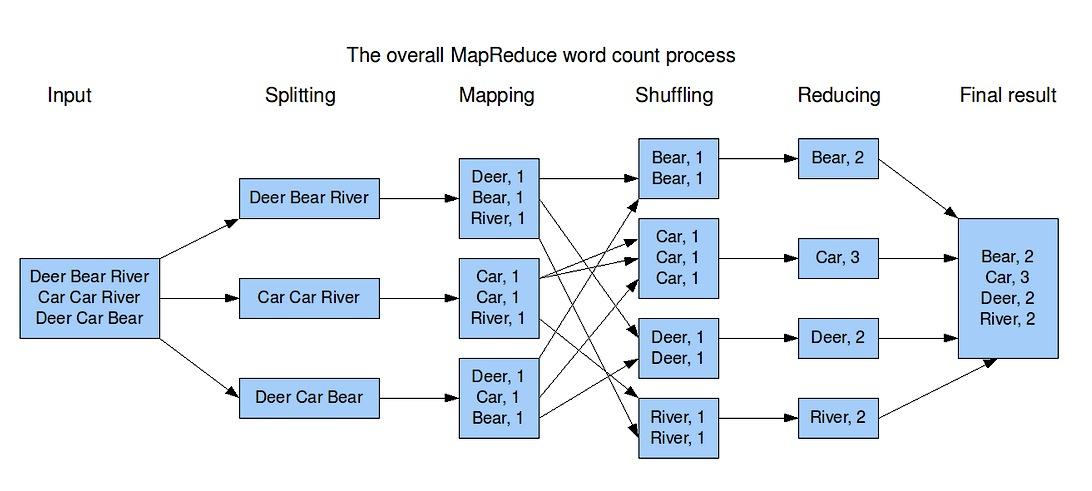

Introduction to Big data
- Big Data is the term used to refer massive volume of data available from variety of sources in various formats.
- 80% of the data available today are unstructured -data from sensors, images, blog posts etc.
Example:
- Billion Facebook accounts ,pages
- twitter accounts and tweets
- Billions of Google search queries
- petabytes of YouTube Google, Facebook, LinkedIn, data
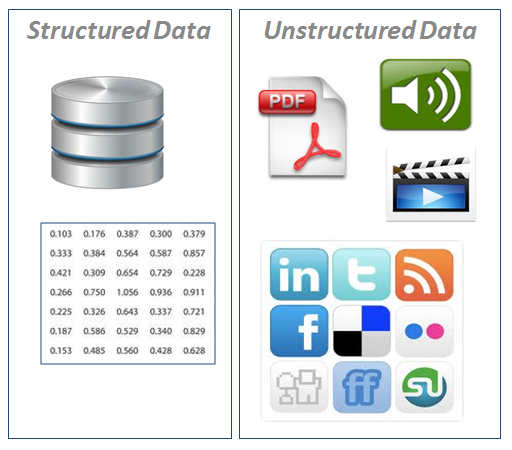
Types of Data
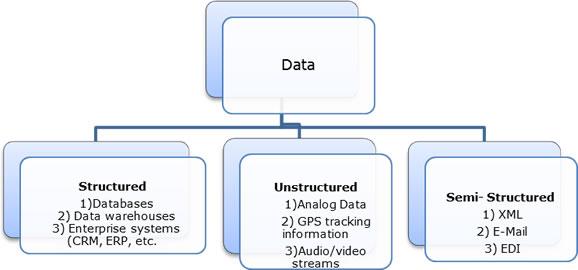
How BigData Helps?
- Identifying terrorists or criminals by analyzing images or videos received from surveillance cameras
- Predicting the result of an election based on the opinions of voters expressed in social media
- Determining the success of a newly introduced product in the media by analyzing the views expressed by users in review forums
Big Data Challenges
- Need to manage structured, unstructured and semi-structured data
- Analyzing and generating useful information from the large amount of structured and unstructured data
- It is difficult to process high velocity big data using traditional DBMS
- New Hardware devices and Software tools Required
Big Data and RDBMS
RDBMS are not suitable for BigData because
It cannot handle Petabytes of data
It cannot handle unstructured/semi structured data
BLOBs could not solve the growing or changing customer and business needs.
Google, Yahoo, Facebook, LinkedIn handles “Petabytes” of data every day.
Many organization are creating terabytes of data every day and getting data to processor is a concern
A distributed system is more reliable than a non-distributed system, as there is no single point of failure.
Distributed System
Features of a Distributed System
- Partial failure support
- Data Recoverability
- Component Recovery
- Consistency
- Scalability
Challenges in Distributed Systems
- Limited Software support available
- Lots of Security issues to be handled
- Design of distributed systems always invite lots of complexities
- Multiple point of failure and troubleshooting issues
Introduction to Hadoop
- Hadoop is an open source framework managed by Apache Software Foundations.
- It handles Big Data.
- Core components of Hadoop are
- HDFS: Highly Available Data Storage System.
- MapReduce : Parallel Processing System
History

- Implemented based on Google’s File System and Google’s Map Reduce.
- Allows application to be written in high level languages like java, c++, python etc as well.
- Supports Horizontal scalability to thousands of CPUs
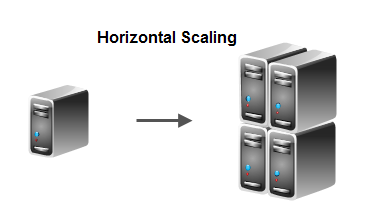
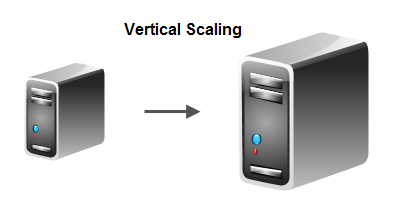
- Java based, so portable on all platforms
- Data is distributed and replicated on multiple nodes.
- Processing of data is done locally on these nodes, so no data transfer delay.
- Processing is done in parallel on multiple nodes so faster processing.
HDFS (Hadoop Distributed File System)
- Stands for Hadoop Distributed File System
- HDFS is additional layer of file system on top of native file system such as ext3, ext4 or xfs
- Simple file system inspired by GFS written in java.
- Provides redundant (Duplicate) storage for massive amounts of data.
- Optimized for large, streaming reads of files.
- Runs on clusters of Commodity Hardware

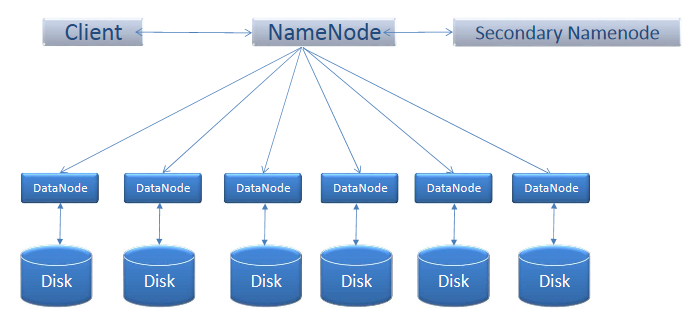
Cluster: A set of machines running HDFS and Map Reduce.
Node: Individual machines are known as nodes
A cluster can have as few as one node, as many as several thousands
HDFS Architecture
- Data is organized into files and directories.
- Files are divided into uniform sized (64MB/128M) blocks and distributed across clusters.
- Blocks are replicated for handling hardware failures.
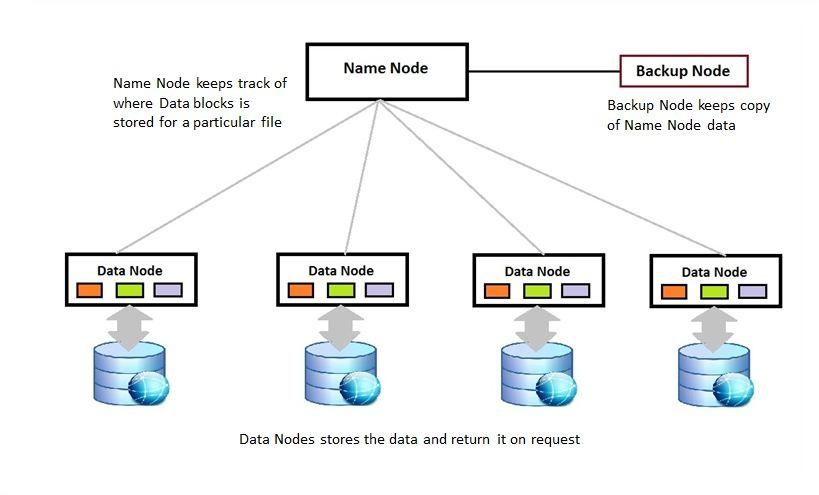
- Follows Master-Slave architecture Master is known as Namenode Slave is known as DataNode
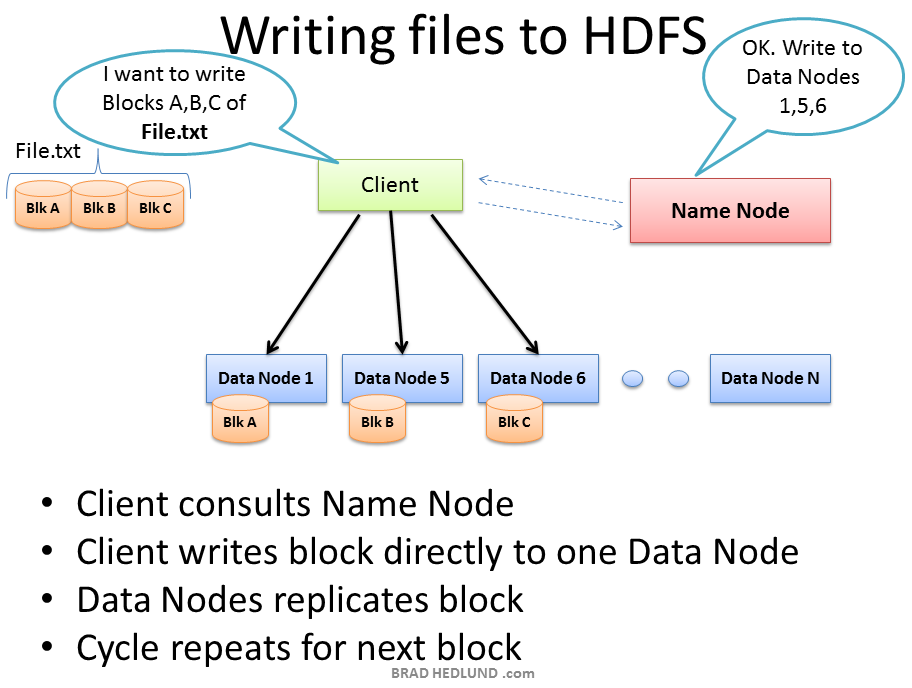
HDFS is implemented using 3 s/w daemons
1. Name node
2. Secondary Name node
3. Data node
1. Name node
- Name node saves the metadata about data
- Without metadata, available in NameNode, we unable to access DataNode.
- if Namenode stops working Hadoop Cluster is inaccessible
Name Node Daemon
- Manages the file system space.
- Controls the client’s access to files.
- Determines mapping of blocks to Datanodes.
- Manages Block Replication
- Performs file system namespace operation like Opening, Closing, Renaming, Creating, Deleting etc.
Namenode maintains two files
Fsimage : Contains the entire file system namespace.
Editlog: Log file to record the changes that occur to HDFS Meta data.
When System is started:
- Namenode reads the fsimage and editlog from disk.
- Apply editlog to fsimage.
- Flush new copy of fsimage to disk
- Discard the older copy of fsimage.
- Truncates the old editlog
2. Secondary Name node
Namenode may restart while editlog may grow very large or If there is a crash, huge metadata loss. So the Next restart will take too long. I this situation we use Secondary namenode  Secondary Namenode daemon
Secondary Namenode daemon
Secondary Namenode daemon- It will run in the Master or in a separate machine
- Helps in keeping the fsimage up to date
3. Data node
When datanode starts :
- Scans local file system
- Generates a list of blocks it holds
- Sends the report to namenode (called block report)
- Periodically sends the block report and heart beat to Namenode
If namenode doesn’t receive the heartbeat for a pre specified duration
- It considers the data node as dead.
- Data will not be accessible
Solution is → to maintain multiple copies of blocks
Replication Factor
- Files are split into multiple blocks.
- Block are replicated on multiple data nodes.
- No of copies/replicas of files is known as replication factor.
- Default Replication factor is 3.
- Block size is configurable per file
- Replication factor is also configurable per file
- If a datanode fails –reads the block it stores from the replicated blocks.
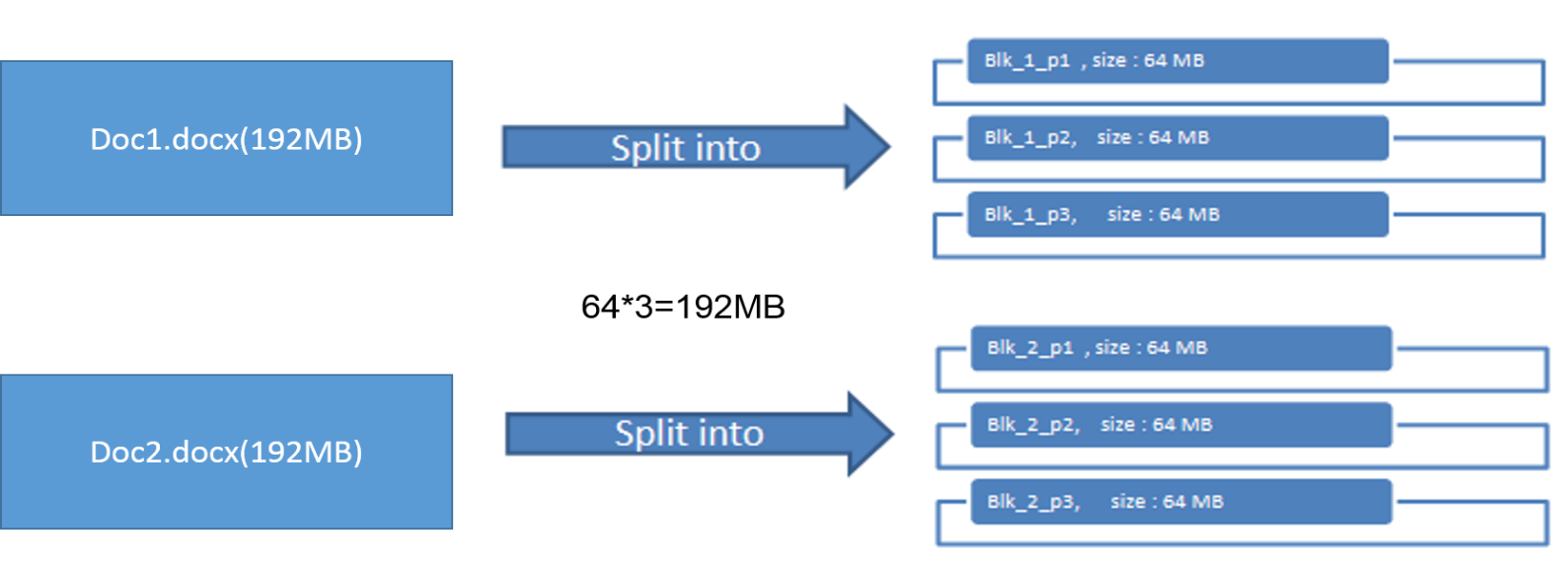
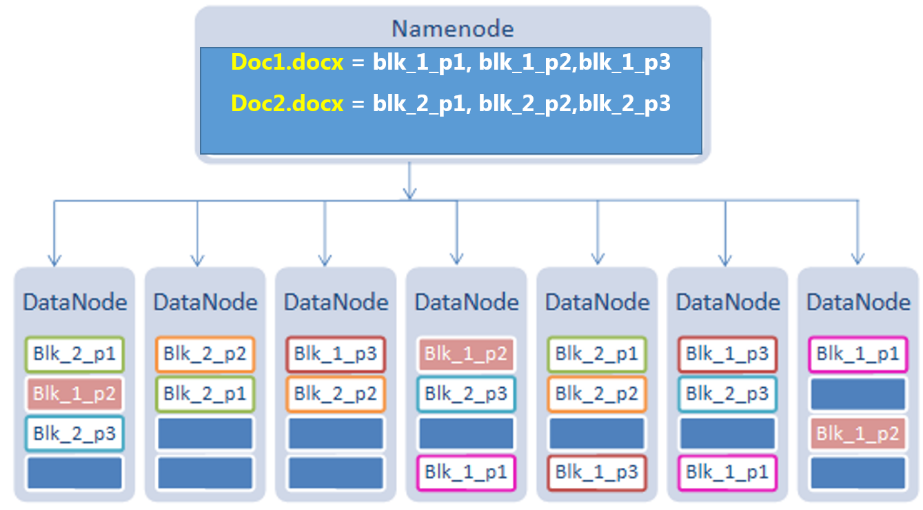
Writing Files
Question: storing a file in HDFS (abc.docx), of size 192MB and replication factor as 3.
Answer: Steps to writing the files to HDFS
- Name node receives the request to store the file from client program.
- The file size is 192MB, 192MB = 64x3
- So file is divided into 3 equal blocks
- Replica factor is by default 3. So it will create the 3 exact copies of each block.
- 3 blocks and 3 copies of each block.
- So we have to store 9 blocks in HDFS
- Blocks are Stored in different nodes.
- All the metadata about blocks and nodes are saved in Namenode

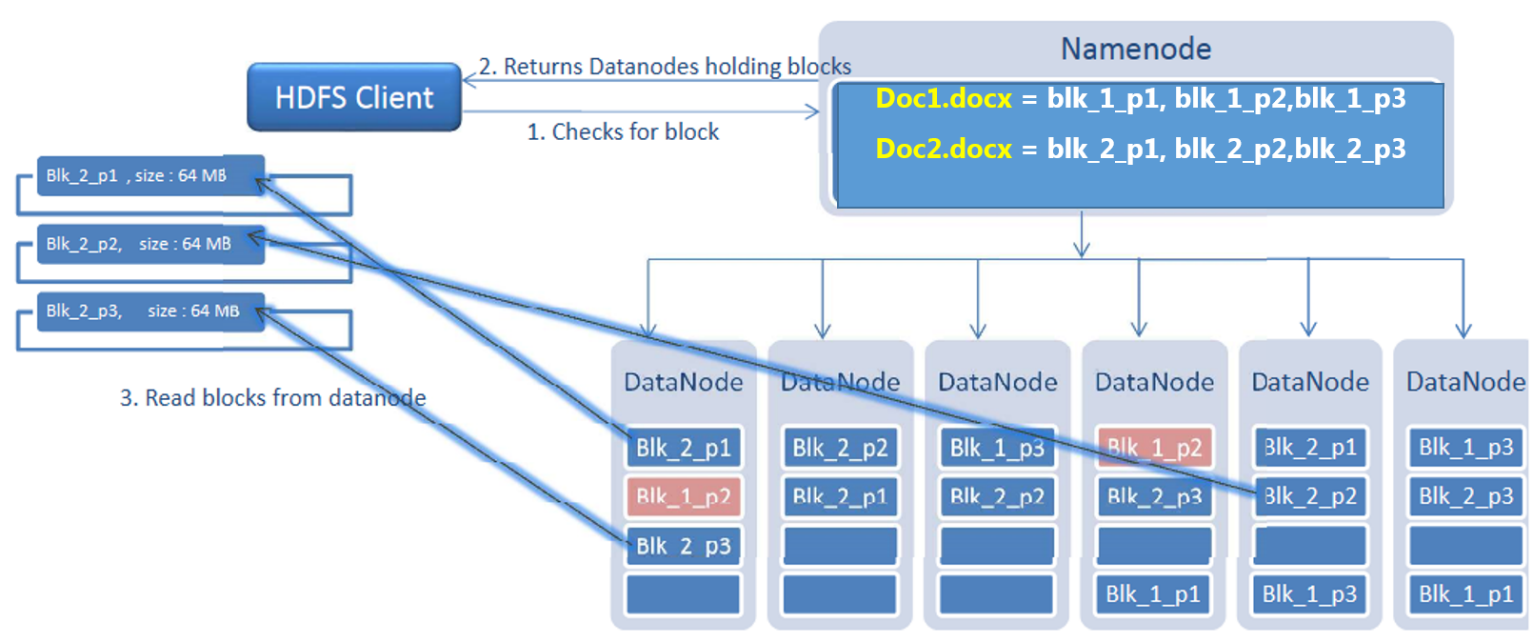
Reading Files
HDFS Shell Commands
- Shell commands help Hadoop to directly interact with HDFS
- Syntax is >
hadoop fs - <options>
hadoop dfs - <options>
- List of commands can be obtained with bin/Hadoop fs-help command
$ hadoop fs –help
$ hadoop dfs –help
- To get Usage/Help for a Particular command use,
$ hadoop fs -help help
$ hadoop dfs -help help
- Hadoop version
$ hadoop version
Difference between FS and DFS
- there's no difference between the two syntaxes
- FS relates to a generic file system which can point to any file systems like local, HDFS etc.
- DFS is very specific to HDFS.
- So when we use FS it can perform operation with from/to local or hadoop distributed file system to destination. But specifying DFS operation relates to HDFS.
ls (List command)
List out the all the files and directories
- List the contents that match the specified file pattern.
- If path is not specified, the contents of /user/<currentUser> will be listed
hadoop fs –ls
5 drwxr-xr-x - training supergroup 0 2015-09-09 16:43 -ls
6 drwxr-xr-x - training supergroup 0 2015-09-24 15:05 -mkdir
7 drwxr-xr-x - training supergroup 0 2015-08-05 12:18 12
8 drwxr-xr-x - training supergroup 0 2015-09-24 15:08 142918_hdfs
9 drwxr-xr-x - training supergroup 0 2015-09-24 15:02 194661_hdfs
5 drwxr-xr-x - training supergroup 0 2015-09-09 16:43 -ls
6 drwxr-xr-x - training supergroup 0 2015-09-24 15:05 -mkdir
7 drwxr-xr-x - training supergroup 0 2015-08-05 12:18 12
8 drwxr-xr-x - training supergroup 0 2015-09-24 15:08 142918_hdfs
9 drwxr-xr-x - training supergroup 0 2015-09-24 15:02 194661_hdfs
- -d Directories are listed as plain files.
- -h Formats the sizes of files in a human-readable fashion
- -R Recursively list the contents of directories.
mkdir (Make Dirrectory)
Create a directory in specified location.
-p Do not fail if the directory already exists
$ mkdir satya
mkdir: cannot create directory `satya': File exists
mkdir: cannot create directory `satya': File exists
$ mkdir -p satya
Success
Put
Copy files from the local file system into fs
Syntax : hadoop fs –put <source> <dest>
Example : hadoop fs -put /home/ali/doc.pig /home/satya
To create a directory in Hdfs:
Hadoop fs –mkdir parveen
To copy a file to Parveen directory
Hadoop fs –put /home/mrinmoy/Documents/sales
hadoop fs -put home/cloudera/workspace/NASDAQ_daily_prices_C.csv
/ram/mrv1/output
- -f overwrites the destination if it already exists
Get
Copies files or directories from HDFS files system to local file system
Syn : hadoop fs –get [-crc] <hdfs-src> <locl-dest>
Ex : hadoop fs –get /home/ali/doc.pig /home/satya
crc(Cyclic redundancy check) optional -useful in copying the crc also
Commands
ls <path>
Lists the contents of the directory specified by path, showing the names, permissions, owner, size and modification date for each entry.
hadoop fs -ls [dir-name]
hadoop fs -ls /ram
|
lsr <path>
Behaves like -ls, but recursively displays entries in all subdirectories of path.
Usage: hadoop fs -lsr <args>
Recursive version of ls.
Note: This command is deprecated. Instead use hadoop fs -ls -R
|
du <path>
Shows disk usage, in bytes, for all the files which match path; filenames are reported with the full HDFS protocol prefix.
Usage: hadoop fs -du [-s] [-h] URI [URI ...]
-s option will result in an aggregate summary of file lengths being displayed, rather than the individual files.
-h option will format file sizes in a “human-readable” fashion (e.g 64.0m instead of 67108864)
Example:
hadoop fs -du vipul1/vipul/loandetails/loandetails.csv
|
dus <path>
Like -du, Displays a summary of file lengths.
Example : $ hadoop fs –dus
o/p : 875748973
|
mv <src><dest>
Moves the file or directory indicated by src to dest, within HDFS.
Example:
hadoop fs -mv /user/hadoop/file1 /user/hadoop/file2
hadoop fs -mv
hdfs://nn.example.com/file1 hdfs://nn.example.com/file2 hdfs://nn.example.com/file3 hdfs://nn.example.com/dir1
|
cp <src> <dest>
Copies the file or directory identified by src to dest, within HDFS.
Example:
|
rm <path>
Removes the file or empty directory identified by path.
Options:
Example:
|
rmr <path>
Removes the file or directory identified by path. Recursively deletes any child entries (i.e., files or subdirectories of path).
|
put <localSrc> <dest>
Copies the file or directory from the local file system identified by localSrc to dest within the DFS.
|
copyFromLocal <localSrc> <dest>
Identical to -put
|
moveFromLocal <localSrc> <dest>
Copies the file or directory from the local file system identified by localSrc to dest within HDFS, and then deletes the local copy on success.
Similar to put command, except that the source localsrc is deleted after it’s copied.
|
get [-crc] <src> <localDest>
Copies the file or directory in HDFS identified by src to the local file system path identified by localDest.
|
getmerge <src> <localDest>
Retrieves all files that match the path src in HDFS, and copies them to a single, merged file in the local file system identified by localDest.
|
cat <filen-ame>
Displays the contents of filename on stdout.
|
copyToLocal <src> <localDest>
Identical to -get
|
moveToLocal <src> <localDest>
Works like -get, but deletes the HDFS copy on success.
|
mkdir <path>
Creates a directory named path in HDFS.
Creates any parent directories in path that are missing (e.g., mkdir -p in Linux).
|
setrep [-R] [-w] rep <path>Sets the target replication factor for files identified by path to rep. (The actual replication factor will move toward the target over time)
Changes the replication factor of a file. If path is a directory then the command recursively changes the replication factor of all files under the directory tree rooted at path.Options:
Example: hadoop fs -setrep -w 3 /user/hadoop/dir1
|
touchz <path>
Creates a file at path containing the current time as a timestamp. Fails if a file already exists at path, unless the file is already size 0.
Create a file of zero length.
Example:
|
test -[ezd] <path>
Returns 1 if path exists; has zero length; or is a directory or 0 otherwise.
|
stat [format] <path>
Prints information about path. Format is a string which accepts file size in blocks (%b), filename (%n), block size (%o), replication (%r), and modification date (%y, %Y).
Example: hadoop fs -stat "%F %u:%g %b %y %n" /file
|
tail [-f] <file2name>
Shows the last 1KB of file on stdout. Displays last kilobyte of the file to stdout.
Options:
Example:
|
chmod [-R] mode,mode,... <path>...
Changes the file permissions associated with one or more objects identified by path.... Performs changes recursively with R. mode is a 3-digit octal mode, or {augo}+/-{rwxX}. Assumes if no scope is specified and does not apply an umask.
|
chown [-R] [owner][:[group]] <path>...
Sets the owning user and/or group for files or directories identified by path.... Sets owner recursively if -R is specified.
|
chgrp [-R] group <path>...
Sets the owning group for files or directories identified by path.... Sets group recursively if -R is specified.
|
help <cmd-name>
Returns usage information for one of the commands listed above. You must omit the leading '-' character in cmd.
|
count
Usage: hadoop fs -count [-q] [-h] [-v] <paths>
Count the number of directories, files and bytes under the paths that match the specified file pattern. The output columns with -count are: DIR_COUNT, FILE_COUNT, CONTENT_SIZE, PATHNAME
The output columns with -count -q are: QUOTA, REMAINING_QUATA, SPACE_QUOTA, REMAINING_SPACE_QUOTA, DIR_COUNT, FILE_COUNT, CONTENT_SIZE, PATHNAME
The -h option shows sizes in human readable format.
The -v option displays a header line.
Example:
- hadoop fs -count hdfs://nn1.example.com/file1 hdfs://nn2.example.com/file2
- hadoop fs -count -q hdfs://nn1.example.com/file1
- hadoop fs -count -q -h hdfs://nn1.example.com/file1
- hdfs dfs -count -q -h -v hdfs://nn1.example.com/file1
expunge
Usage: hadoop fs -expunge
Empty the Trash. Refer to the HDFS Architecture Guide for more information on the Trash feature.
find
Usage: hadoop fs -find <path> ... <expression> ...
Finds all files that match the specified expression and applies selected actions to them. If no path is specified then defaults to the current working directory. If no expression is specified then defaults to -print.
The following primary expressions are recognised:
- -name pattern
-iname pattern
Evaluates as true if the basename of the file matches the pattern using standard file system globbing. If -iname is used then the match is case insensitive.
- -print
-print0Always
evaluates to true. Causes the current pathname to be written to standard output. If the -print0 expression is used then an ASCII NULL character is appended.
The following operators are recognised:
- expression -a expression
expression -and expression
expression expression
Logical AND operator for joining two expressions. Returns true if both child expressions return true. Implied by the juxtaposition of two expressions and so does not need to be explicitly specified. The second expression will not be applied if the first fails.
Example:
hadoop fs -find / -name test -print
truncate
Usage: hadoop fs -truncate [-w] <length> <paths>
Truncate all files that match the specified file pattern to the specified length.
Options:
- The -w flag requests that the command waits for block recovery to complete, if necessary. Without -w flag the file may remain unclosed for some time while the recovery is in progress. During this time file cannot be reopened for append.
Example:
- hadoop fs -truncate 55 /user/hadoop/file1 /user/hadoop/file2
- hadoop fs -truncate -w 127 hdfs://nn1.example.com/user/hadoop/file1
usage
Usage: hadoop fs -usage command
Return the help for an individual command.
Hadoop Cluster modes
Hadoop clusters can be installed in three modes
Local (Standalone) mode
- Default mode used for developing and debugging purposes
- All he three configuration files are empty
- –core-site.xml
- –hdfs-site.xml
- –mapred-site.xml
- Hadoop runs completely on the local system
- Doesn’t use HDFS
- Hadoop daemons are not launched
Pseudo distributed mode
- Clusters run in a single machine
- Useful for development and debugging purposes
- All daemons run in a single machine
- Non empty configuration files
- Replication factor for HDFS is set as 1 in hdfs-site.xml
- Need to specify the location of the Secondary NameNode in the masters file and the slave nodes in the slaves file
- Helpful in examining memory usage, HDFS input/output issues, and other daemon interactions
- Here one node will be used as Master Node / Data Node / Job Tracker / Task Tracker
Fully distributed mode
- Non empty configuration files
- Hostname and port the NameNode is explicitly specified in the core-site.xml
- Hostname and port of the node where JobTrackerruns is specified in the mapred-site.xml
- Actual number of replications are mentioned in the dfs-site.xml
- Need to update the masters file and the slave files with the locations of other daemons
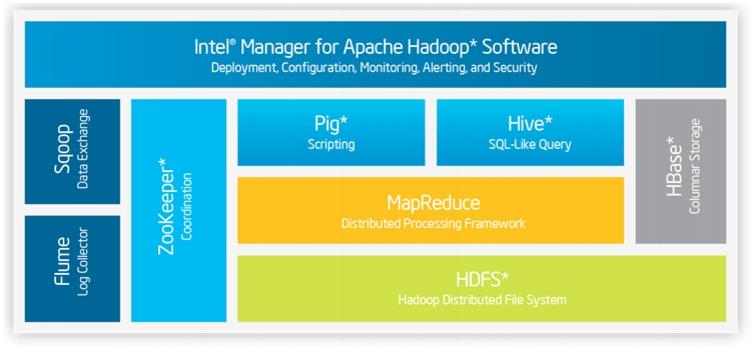
Hadoop Ecosystem
Components of Hadoop Ecosystem
- Processing Large data –Pig
- Data Ware House –Hive
- Big Data Storage Factory –HBase
- Data Serializer –AVRO
- Cluster Coordinator –Zookeeper, Chukwa
- Machine Learning –Mahout
- Data Base Migrator -Sqoop

1. PIG
A scripting platform for processing and analyzing large data sets
Pig was designed for performing a long series of data operations, making it ideal for three categories of Big Data jobs:
- Extract-transform-load (ETL) data pipelines,
- Research on raw data, and
- Iterative data processing
- Includes a high level data flow language called Pig Latin
- Provides an engine for executing data flows in parallel on Hadoop
- Pig runs on Hadoop and makes use of HDFS and MapReduce
- Many built-in functions for data transformations
- Good support for user defined functions
- Developed at Yahoo -40% of all Hadoop jobs are run with Pig at Yahoo
2. Hive
- Useful in querying data stored in Hadoop
- Makes use if Hive Query Language ( HiveQL)
- Suitable for data warehouse applications where static data is analyzed
- Does not provide transactions or record level insert/update/delete operations
- Hive makes transformations of SQL based applications to Hadoop easier
- Translates queries to MapReduce jobs
- Those who know SQL can learn Hive easily
3. HBase
A non-relational (NoSQL) database that runs on top of HDFS
- Apache HBase is an open source NoSQL database that provides real-time read/write access to those large datasets.
- Open source , column oriented, scalable , distributed database
- Modeled after Google’s BigTable.
- It’s a NoSQLdatabase
- More than a database -acts as a data store
- Suitable for vary large volume of data only
- Strongly consistent database
- Supports Java Client API
- Support for Thrift/REST API for Non Java front-ends
Apache Avro
Apache Avro™ is a data serialization system.
- Serialization is the process of translating data structures or objects state into binary or textual.
- Once the data is transported over network or retrieved from the persistent storage, it needs to be deserialized again
- Language independent data serialization support
- Provides vide variety of data structures.
- Support for Remote procedure call (RPC).
- Smart and easy integration with dynamic languages
Apache ZooKeeper
An open source server that reliably coordinates distributed processes

Apache Mahout
An algorithm library for scalable machine learning on Hadoop
Once big data is stored on the Hadoop Distributed File System (HDFS), Mahout provides the data science tools to automatically find meaningful patterns in those big data sets. The Apache Mahout project aims to make it faster and easier to turn big data into big information. 
Scoop
- Tool from apache to transfer data between HDFS & RDBMS
- Automatic data import facility
Ref : http://bradhedlund.com/2011/09/10/understanding-hadoop-clusters-and-the-network/